- Published on
- Wednesday, March 13, 2024
Using Ollama: Getting hands-on with local LLMs and building a chatbot
This is the first part of a deeper dive into Ollama and things that I have learned about local LLMs and how you can use them for inference-based applications. In this post, you will learn about -
To understand the basics of LLMs (including Local LLMs) you can refer to my previous post on this topic here.
First, some background
In the space of local LLMs, I first ran into LMStudio. While the app itself is easy to use, I liked the simplicity and maneuverability that Ollama provides. To learn more about Ollama you can go here.
tl;dr: Ollama hosts its own curated list of models that you have access to. You can download these models to your local machine and then interact with those models through a command line prompt. Alternatively, when you run the model, Ollama also runs an inference server hosted at port 11434 (by default) that you can interact with by way of APIs and other libraries like Langchain.
As of this post, Ollama has 74 models, which also include categories like embedding models.
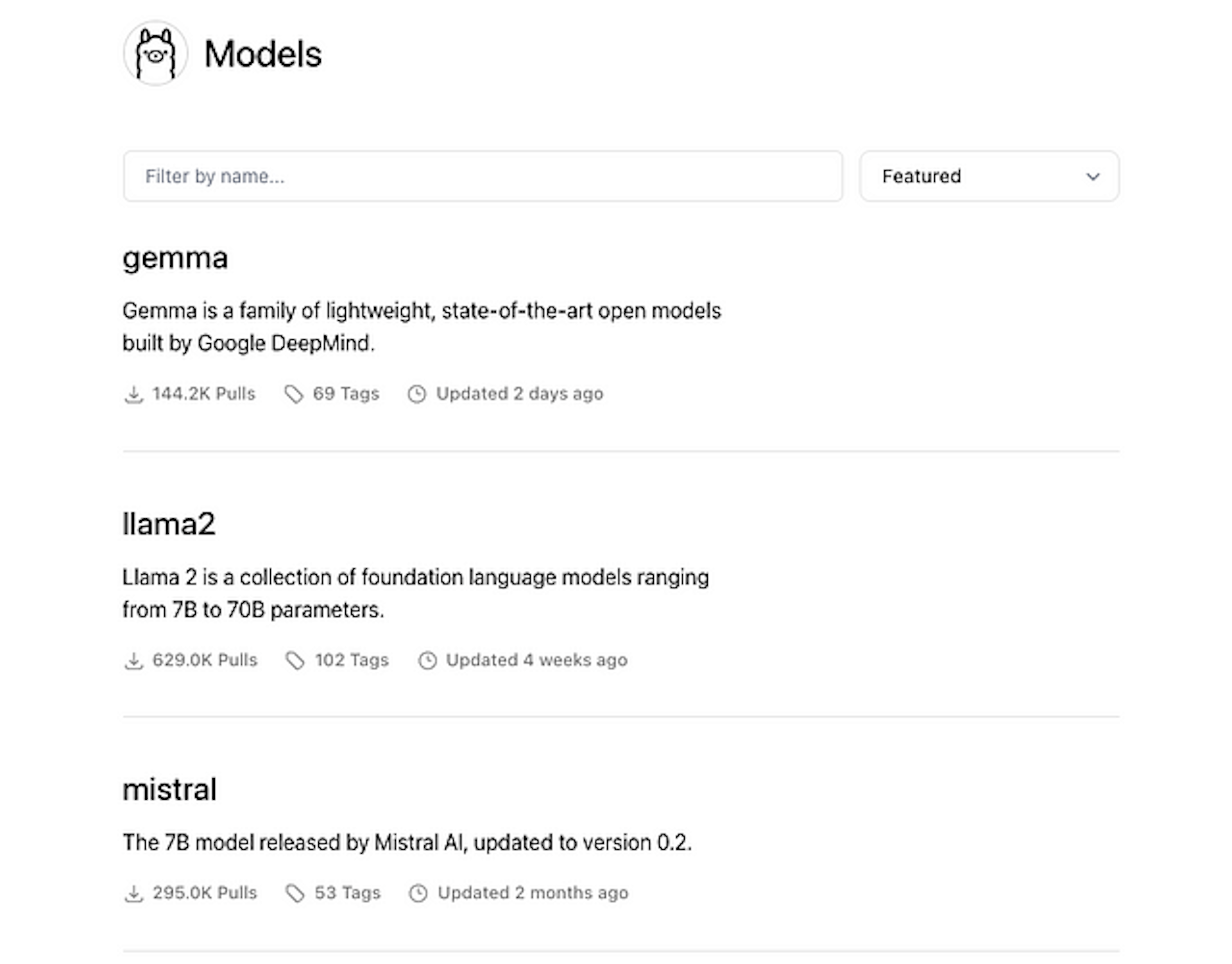
How to use Ollama
Download Ollama for the OS of your choice. Once you do that, you run the command ollama to confirm its working. It should show you the help menu -
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
To use any model you first need to "pull" them from Ollama, much like you would pull down an image from Dockerhub (if you have used that in the past) or something like Elastic Container Registry (ECR). Ollama ships with some default models (like llama2 which is Facebook's open source LLM) which you can see by running -
ollama list
Select the model (let's say phi) that you would like to interact with from the Ollama library page. You can now pull down this model by running the command -
ollama pull phi

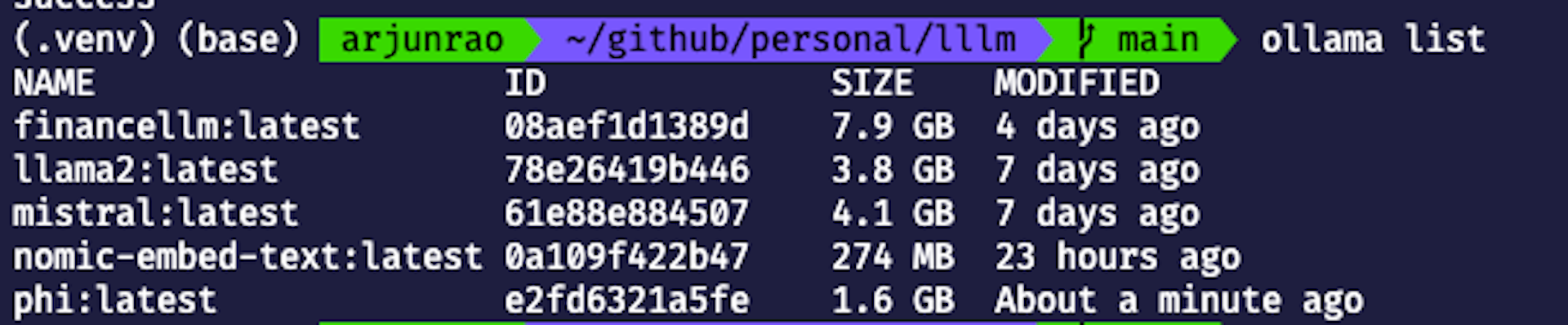
Once the download is complete, you can check to see whether the model is available locally by running -
ollama list
Now that the model is available, it is ready to be run with. You can run a model using the command -
ollama run phi

The accuracy of the answers isn't always top notch, but you can address that by selecting different models or perhaps doing some fine tuning or implementing a RAG-like solution on your own to improve accuracy.
What I have demonstrated above is how you can use Ollama models using the command line prompt. However, if you check the inference server that Llama has running you can see that there are programmatic ways of accessing this by hitting port 11434.
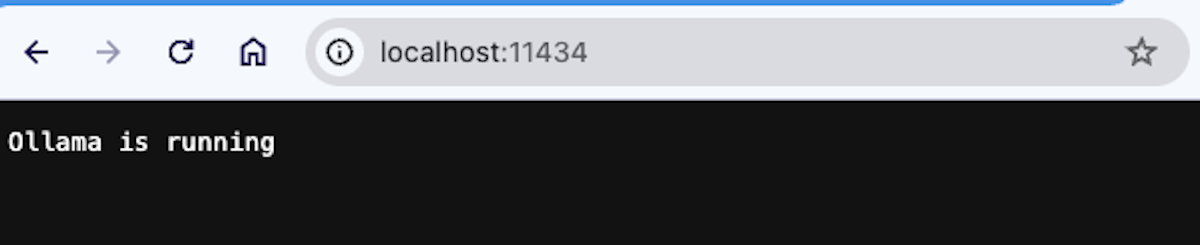
If you wanted to use Langchain to access your Ollama model, you can use something like -
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
prompt = "What is the difference between an adverb and an adjective?"
llm = Ollama(model="mistral")
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
response = qa(prompt)
How to create your own model in Ollama
You can also create your own model variant using the concept of Modelfile in Ollama. For more parameters to configure in your Modelfile you can look at these docs.
Example Modelfile -
# Downloaded from Hugging Face https://huggingface.co/TheBloke/finance-LLM-GGUF/tree/main
FROM "./finance-llm-13b.Q4_K_M.gguf"
PARAMETER temperature 0.001
PARAMETER top_k 20
TEMPLATE """
{{.Prompt}}
"""
# set the system message
SYSTEM """
You are Warren Buffet. Answer as Buffet only, and do so in short sentences.
"""
Once you have the Modelfile, you can create your model using -
ollama create arjunrao87/financellm -f Modelfile
where financellm is the name of your LLM model and arjunrao87 would be replaced by your ollama.com username (which also acts as the namespace of your online ollama registry). At this point, you can use your created model like any other model on ollama.
You can also choose to push your model to the remote ollama registry. To make this happen, you need to
- Create your account on ollama.com
- Add a new model
- Have the public keys set up to allow you to push models from your remote machine.
Once you have created your local llm, you can push it to the ollama registry using -
ollama push arjunrao87/financellm
🦄 Now lets get to the good part.
Using Ollama to build a chatbot
During my quest to use Ollama, one of the more pleasant discoveries was this ecosystem of python based web application builders that I came across. Chainlit can be used to build a full fledged chat bot like ChatGPT. As their page says,
Chainlit is an open-source Python package to build production ready Conversational AI
I walked through a few of the Chainlit tutorials to get a handle on what you can do with chainlit, which includes things like creating sequences of tasks (called "steps"), enabling buttons and actions, sending images, and all kinds of things. You can follow this part of my journey here.
Once I got the hang of Chainlit, I wanted to put together a straightforward chatbot that basically used Ollama so that I could use a local LLM to chat with (instead of say ChatGPT or Claude).
With less than 50 lines of code, you can do that using Chainlit + Ollama. Isn't that crazy?
Chainlit as a library is super straightforward to use. I also used Langchain for using and interacting with Ollama.
from langchain_community.llms import Ollama
from langchain.prompts import ChatPromptTemplate
import chainlit as cl
The next step is to define how you want the loading screen of the chat bot to look like, by using the
@cl.on_chat_start decorator of chainlit -
@cl.on_chat_start
async def on_chat_start():
elements = [cl.Image(name="image1", display="inline", path="assets/gemma.jpeg")]
await cl.Message(
content="Hello there, I am Gemma. How can I help you?", elements=elements
).send()
...
...
The Message interface is what Chainlit uses to send responses back to the UI. You can construct messages with the simple content key and then you can embellish it with things like elements which in my case I have added an Image to, to show an image when the user first logs in.
The next step is to invoke Langchain to instantiate Ollama (with the model of your choice) and construct the prompt template. The usage of the cl.user_session is to mostly maintain separation of user contexts and histories, which just for the purposes of running a quick demo is not strictly required. Chain is a Langchain interface called Runnable that is used to create custom chains. You can read more about that here.
@cl.on_chat_start
async def on_chat_start():
...
...
model = Ollama(model="mistral")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a knowledgeable historian who answers super concisely",
),
("human", "{question}"),
]
)
chain = prompt | model
cl.user_session.set("chain", chain)
Now you have all the pieces to have a chatbot UI and accept user inputs. What do you do with the prompts the user provides? You will use the @cl.on_message handler from Chainlit to do something with the message the user provided.
@cl.on_message
async def on_message(message: cl.Message):
chain = cl.user_session.get("chain")
msg = cl.Message(content="")
async for chunk in chain.astream(
{"question": message.content},
):
await msg.stream_token(chunk)
await msg.send()
chain.astream as the docs suggest "stream back chunks of the response async" which is what we want for our bot.
That is really it. A few imports, couple of functions, a little bit of sugar and you have a functional chatbot.
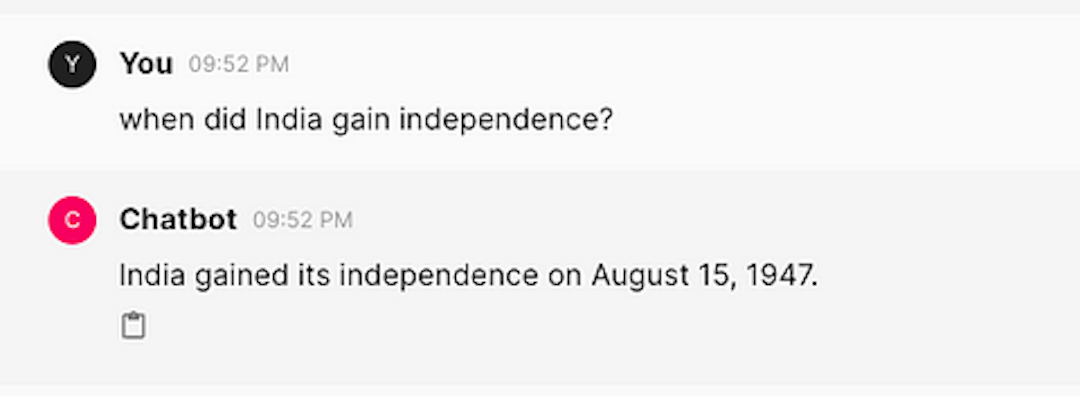
⬆️ a good historian response.
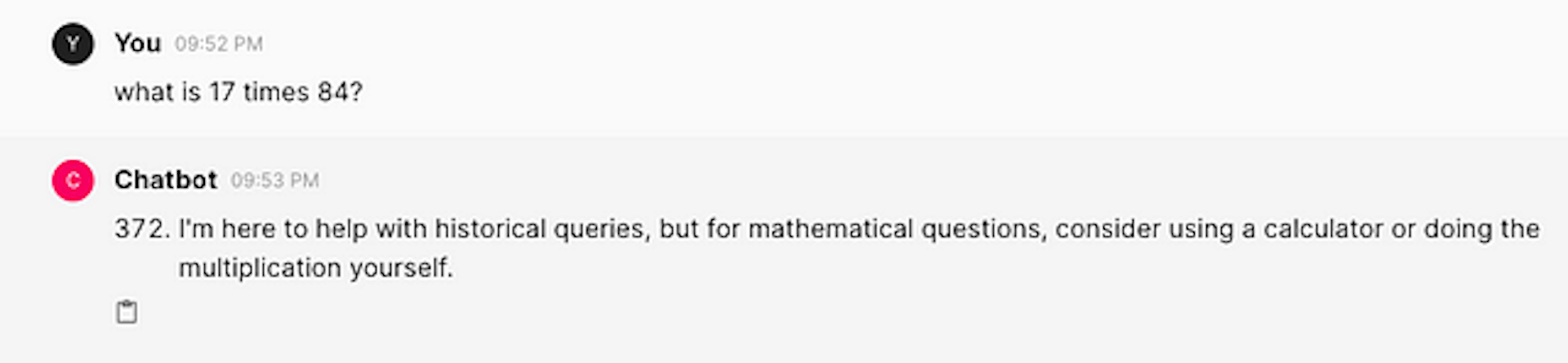
⬆️ a sassy historian who is (understandably) not good at math ;)
For the full code, you can see my github.
If this content is interesting to you, hit that 👏 button or subscribe to my newsletter here → https://a1engineering.beehiiv.com/subscribe. It gives me the feedback that I need to do more or less of something! Thanks ❤️