- Published on
- Friday, March 8, 2024
What are LLMs, Local LLMs and RAG?

Like most people in tech, I have been enthralled by the possibilities of this new wave of AI. Machine learning has been in the zeitgeist for the greater part of the 2000s. It has powered things like your Amazon and Spotify recommendations long before ChatGPT came along. However, the simplicity of outcomes and how achievable this now is for the average-joe is the real headline grabber
I am on a quest to better understand the foundational blocks of where this space is at. I expect this to be the bedrock of most modern software application building from this point on. As I continue to expand into the fog of war (shoutout to all the Age of Empires players out there), I expect this map to be refined and updated with time.

Age of Empires — best game ever made
Here is the skeletal outline of the pieces I have encountered so far —
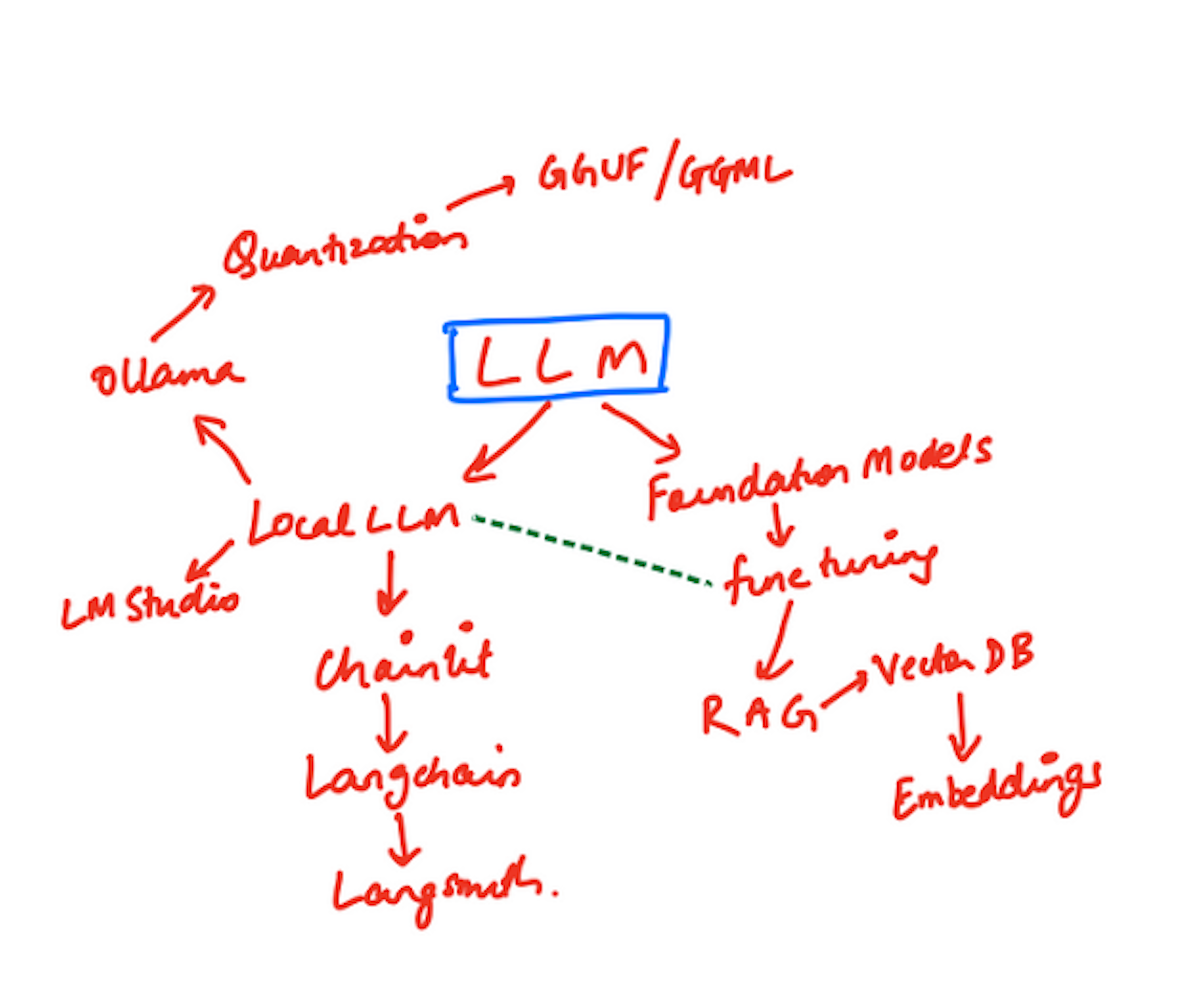 Don’t pay attention to the apparent hierarchy. It merely represents the path my questfinding took.
Don’t pay attention to the apparent hierarchy. It merely represents the path my questfinding took.You have to, of course, start with LLMs (Large Language Models), the space that OpenAI broke into with a sledgehammer. While there were plenty of incumbents in this space (namely models like BERT or proprietary domain models held closed-source by companies like Google or Meta or Spotify), ChatGPT pulled the rug on this space and brought things out in the open.
Basics about ML models
There is plenty of literature out there on LLMs and how they work (check the resources section for some of the good ones I encountered), but let’s get into some of the basics —
Foundation Models
Foundation Models [FMs] (or base models) are built using a LOT of data — the data we are talking about could be in the 100s of petabytes range, if not more. The purpose of this process is to go wide, not deep. Datasets could span several domains, formats, timespans — all in the hope of pre-training the base model with unlabeled and self-supervised data. Foundation models are capable of performing a variety of general tasks such as generating text, visual comprehension and conversing in natural language. Foundation models can be refined to develop more specialized downstream models for specific applications. You can think of Foundation models as being a superset of LLMs.
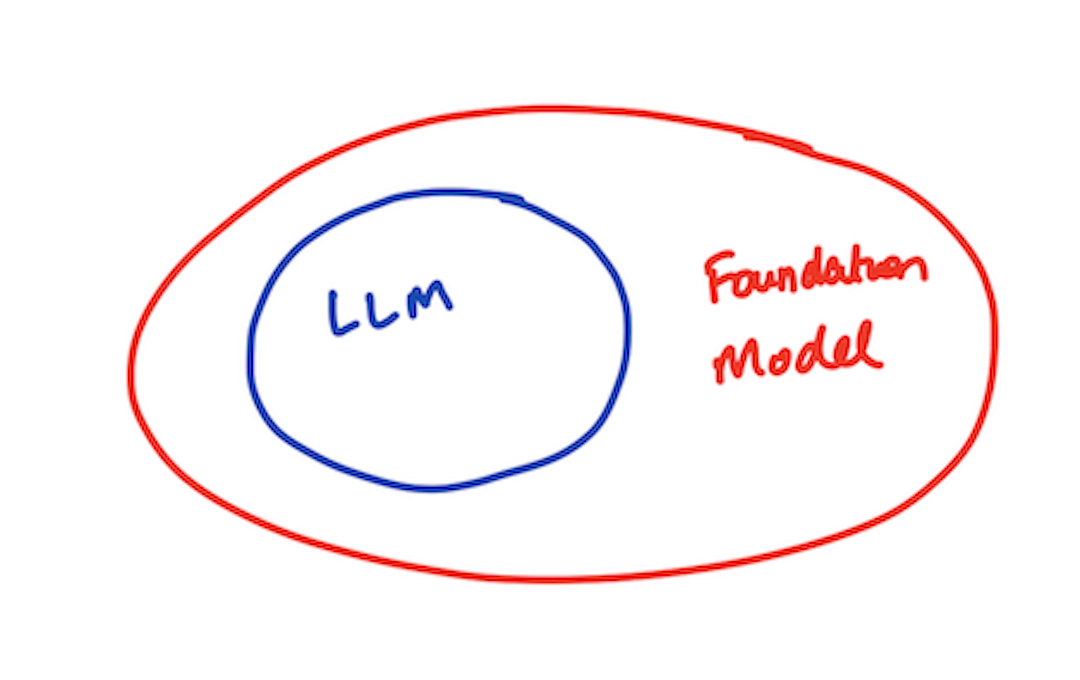
Large Language Models
Large language models are foundational models specifically trained on a massive text dataset. The refined output produced is a subset (or instances) of the Foundation models that are applied specifically to text and text-like things (eg. code). LLMs are still huge models when it comes to parameter count. A parameter is a value the model can change independently as it learns new things and the more parameters a model has, the more complex it can be.
For eg. GPT is the LLM behind OpenAI’s ChatGPT. GPT-3 has 175 million parameters. GPT-4 is estimated to have a total of 1.76 trillion parameters.
Creating LLMs consist of 3 main steps
- Collecting the “right” datasets
- Determining the architecture used to process the datasets
- Executing training by processing the datasets using the architecture
A bit more about the architecture
The “Transformer” architecture allows the model to handle sequences of data like sentences and they allow understanding meaning of each word in context to the other words in the sentence. This way the model can comprehensively understand what the sentence is and what it means in aggregate. This architecture is trained on the datasets mentioned above and during the training process the model is constantly adjusting its parameters based on how close the actual output is compared to the predictive output. It is trained until it basically produces about as close to the expected sentence structure in various scenarios.
Fun fact: Now that you know this, you know what GPT (Generative Pre-trained Transformer) means. In reverse, to follow things chronologically —
Transformer — The deep learning architecture used on the data
Pre-trained — The fact that it is already trained for usage, by using the datasets and parameters I mentioned before
Generative — The ability of the model to construct expected sentence structures based on inputs (prompts) from the external world.
Making the models usable
So now you have these enormous models — either Foundation models or LLMs, but you want to use it to assist you in very specific problem domains that you are interested in. How would you do that? Well, there are 2 broad ways to do so:
- Fine tuning
- RAG (Retrieval Augmented Generation)
1. Fine tuning
Large models can be trained on specific subsets/corpus of data to make them experts at certain tasks. This process is called “Fine tuning”. Fine tuning helps with understanding the context of the question without requiring the prompter to provide additional information. It must be noted, that fine tuning is a far far less computationally intensive process than the training step for LLMs/FMs. (For more details, you can read this)
2. RAG
RAG or Retrieval Augmented Generation is a really complicated way of saying “Knowledge base + LLM”. It describes a system that adds extra data, in addition to what the user provided, before querying the LLM. Where did that extra data come from? Well it could be from any number of external sources.
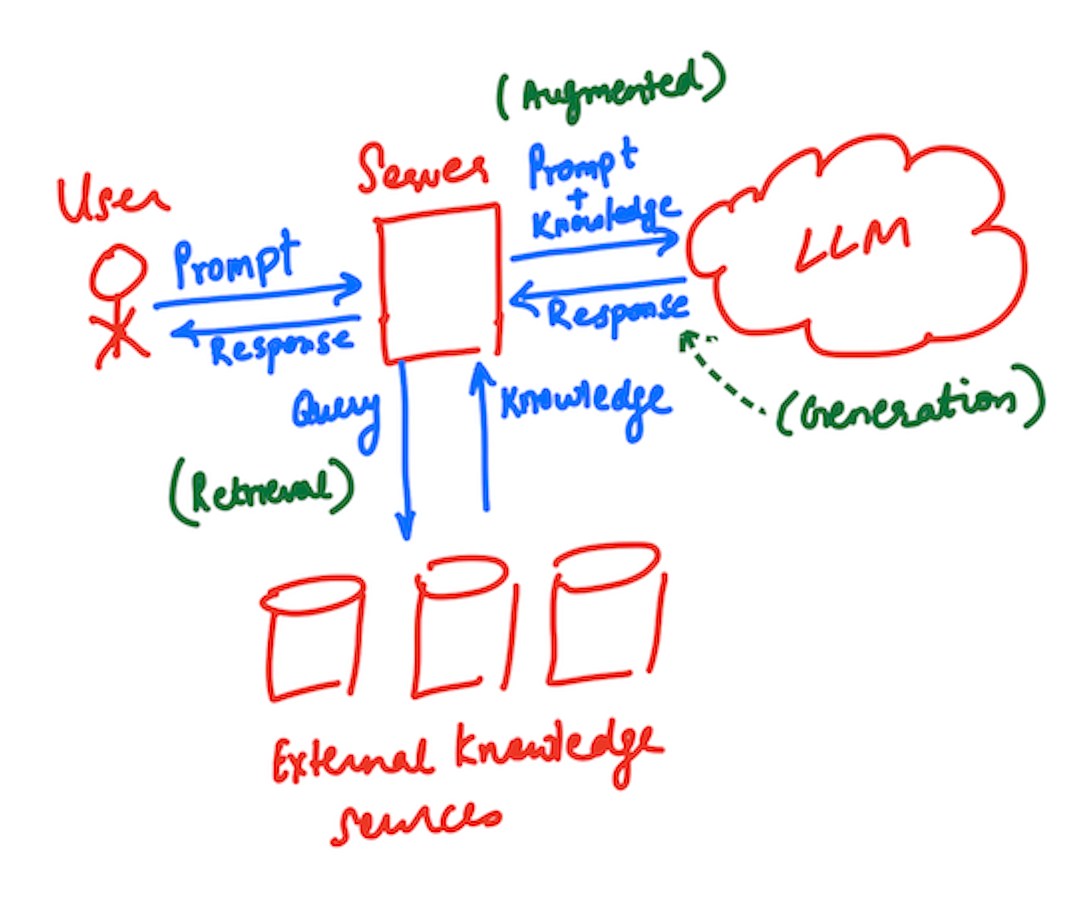
As shown in the diagram above, based on the prompt provided by the user, the server system could fabricate a query which it believes would enhance the quality of the response provided by the LLM. To do so, it could query external knowledge sources (outside of the training data of the LLM) like
- ephemeral data using vector database
- search indexes using Lucene
- another pre-trained LLM that responds with a very specific set of context
This is the “Retrieval” step. Once the extra data has been received, the server then sends the prompt with this additional data (the “augmentation” step) to the LLM which “generates” the response sent back to the user.
I recently read this article which rang the death knell on RAG by proposing an “Intelligent Agent” approach, but this approach doesn’t have widespread adoption thus far.
Inference
We already discussed how models get trained. The process of using these trained models to accept “live” inputs (i.e. prompts) from the user to make deductions of the response from the data, is called “Inference”. Naturally, this step can be pretty expensive if this is being run in the cloud, since for low latency outputs to be provided to the user, these inference systems need to be run on GPU compute.
Local LLMs
Something that I have been fascinated by is the “recent” (maybe 8 or so months old) phenomenon of running LLM inferences locally. Local could be your personal computer, your trusted network host etc. It just means you don’t need to use cloud providers or 3rd party sources to run inferences. This has a few amazing benefits —
- Avoid the costs of running inference on the cloud or a third party provider.
- Avoid vendor lock-in, since you could run these inferences on your own commodity hardware.
- Data is yours, and you don’t need to worry about data corruption or leakage.
There are a couple of pre-eminent players in this space particularly Ollama and LMStudio. I have been using Ollama for the last week or so and have been amazed by the capabilities it unlocks. I can get into this in an upcoming post.
There are a couple of things required to make local LLMs happen —
Now I must express, that these two points are not specific ONLY to local LLMs but to the broader model definition process. However, they become doubly as important when we talk about the local constraints.
Model sizes — When you can’t rely on cloud scale, obviously you are limited by the storage and memory constraints of your local hardware, There are several ways to reduce model sizes such as sharding, compression etc. One such technique is called quantization. An LLM is represented by a bunch of weights and activations. These values are generally represented by the usual 32-bit floating point (float32) datatype. Quantization is the process of representing an LLM using something that has lower fidelity than 32 bits. It does mean that the accuracy of the model reduces, but so does its size and thereby memory requirements. Depending on the type of task you are conducting, that could be a worthy tradeoff.
Model formats — There are several file formats to store LLM models for inference. Examples of these include GGML(GPT-Generated Model Language), GGUF (GPT-Generated Unified Format), GPTQ and the list goes on. GGUF has been a pretty popular format, especially for local LLMs since it allows for inference execution on the CPU, and uses the GPU (if available) only to speed up specific layers. While the CPU is slower than the GPU for executing this (this is a great article to get a look behind the curtains for the why), it enables inference on local computers like Windows and Macbooks. What a time to be alive!
That’s all I have for now. I’ll cover some other interesting aspects of Local LLMs and developing using them in an upcoming post.
If this content is interesting to you, hit that 👏 button or subscribe to my newsletter here → https://a1engineering.beehiiv.com/subscribe. It gives me the feedback that I need to do more or less of something! Thanks ❤️
Resources
- https://www.youtube.com/watch?v=5sLYAQS9sWQ&t=2s&ab_channel=IBMTechnology
- https://aws.amazon.com/what-is/foundation-models/
- https://deepchecks.com/glossary/model-parameters/
- https://www.projectpro.io/article/foundational-models-vs-large-language-models/893
- https://www.maartengrootendorst.com/blog/quantization/
- https://medium.com/@phillipgimmi/what-is-gguf-and-ggml-e364834d241c
- https://aws.amazon.com/what-is/retrieval-augmented-generation